Last week, Damon Matthews from Concordia visited, and gave a guest CGCS lecture, “Cumulative Carbon and the Climate Mitigation Challenge”. The key idea he addressed in his talk is the question of “committed warming” – i.e. how much warming are we “owed” because of carbon emissions in the past (irrespective of what we do with emissions in the future). But before I get into the content of Damon’s talk, here’s a little background.
The question of ‘owed’ or ‘committed’ warming arises because we know it takes some time for the planet to warm up in response to an increase in greenhouse gases in the atmosphere. You can calculate a first approximation of how much it will warm up from a simple energy balance model (like the ones I posted about last month). However, to calculate how long it takes to warm up you need to account for the thermal mass of the oceans, which absorb most of the extra energy and hence slow the rate of warming of surface temperatures. For this you need more than a simple energy balance model.
You can do a very simple experiment with a Global Circulation Model, by setting CO2 concentrations at double their pre-industrial levels, and then leave them constant at this level, to see how long the earth takes to reach a new equilibrium temperature. Typically, this takes several decades, although the models differ on exactly how long. Here’s what it looks like if you try this with EdGCM (I ran it with doubled CO2 concentrations starting in 1958):
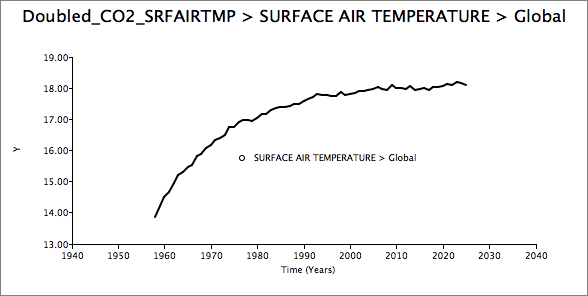
Of course, the concentrations would never instantaneously double like that, so a more common model experiment is to increase CO2 levels gradually, say by 1% per year (that’s a little faster than how they have risen in the last few decades) until they reach double the pre-industrial concentrations (which takes approx 70 years), and then leave them constant at that level. This particular experiment is a standard way of estimating the Transient Climate Response – the expected warming at the moment we first reach a doubling of CO2 – and is included in the CMIP5 experiments. In these model experiments, it typically takes a few decades more of warming until a new equilibrium point is reached, and the models indicate that the transient response is expected to be a little over half of the eventual equilibrium warming.
This leads to a (very rough) heuristic that as the planet warms, we’re always ‘owed’ almost as much warming again as we’ve already seen at any point, irrespective of future emissions, and it will take a few decades for all that ‘owed’ warming to materialize. But, as Damon argued in his talk, there are two problems with this heuristic. First, it confuses the issue when discussing the need for an immediate reduction in carbon emissions, because it suggests that no matter how fast we reduce them, the ‘owed’ warming means such reductions will make little difference to the expected warming in the next two decades. Second, and more importantly, the heuristic is wrong! How so? Read on!
For an initial analysis, we can view the climate problem just in terms of carbon dioxide, as the most important greenhouse gas. Increasing CO2 emissions leads to increasing CO2 concentrations in the atmosphere, which leads to temperature increases, which lead to climate impacts. And of course, there’s a feedback in the sense that our perceptions of the impacts (whether now or in the future) lead to changed climate policies that constrain CO2 emissions.
So, what happens if we were to stop all CO2 emissions instantly? The naive view is that temperatures would continue to rise, because of the ‘climate commitment’ – the ‘owed’ warming that I described above. However, most models show that the temperature stabilizes almost immediately. To understand why, we need to realize there are different ways of defining ‘climate commitment’:
- Zero emissions commitment – How much warming do we get if we set CO2 emissions from human activities to be zero?
- Constant composition commitment – How much warming do we get if we hold atmospheric concentrations constant? (in this case, we can still have some future CO2 emissions, as long as they balance the natural processes that remove CO2 from the atmosphere).
The difference between these two definition is shown here. Note that in the zero emissions case, concentrations drop from an initial peak, and then settle down at a lower level:


The model experiments most people are familiar with are the constant composition experiments, in which there is continued warming. But in the zero emissions scenarios, there is almost no further warming. Why is this?
The relationship between carbon emissions and temperature change (the “Carbon Climate Response”) is complicated, because it depends two factors, each of which is complicated by (different types of) inertia in the system:
- Climate Sensitivity – how much temperature changes in response to difference levels of CO2 in the atmosphere. The temperature response is slowed down by the thermal inertia of the oceans, which means it takes several decades for the earth’s surface temperatures to respond fully to a change in CO2 concentrations.
- Carbon sensitivity – how much concentrations of CO2 in the atmosphere change in response to different levels of carbon emissions. A significant fraction (roughly half) of our CO2 emissions are absorbed by the oceans, but this also takes time. We can think of this as “carbon cycle inertia” – the delay in uptake of the extra CO2, which also takes several decades. [Note: there is a second kind of carbon system inertia, by which it takes tens of thousands of years for the rest of the CO2 to be removed, via very slow geological processes such as rock weathering.]

It turns out that the two forms of inertia roughly balance out. The thermal inertia of the oceans slows the rate of warming, while the carbon cycle inertia accelerates it. Our naive view of the “owed” warming is based on an understanding of only one of these, the thermal inertia of the ocean, because much of the literature talks only about climate sensitivity, and ignores the question of carbon sensitivity.
The fact that these two forms of inertia tend to balance leads to another interesting observation. The models all show an approximately linear response to cumulative emissions. For example, here are the CMIP3 models, used in the IPCC AR4 report (the average of the models, indicated by the arrow, is around 1.6C of warming per 1,000 gigatonnes of carbon):

The same relationship seems to hold for the CMIP5 models, many of which now include a dynamic carbon cycle:
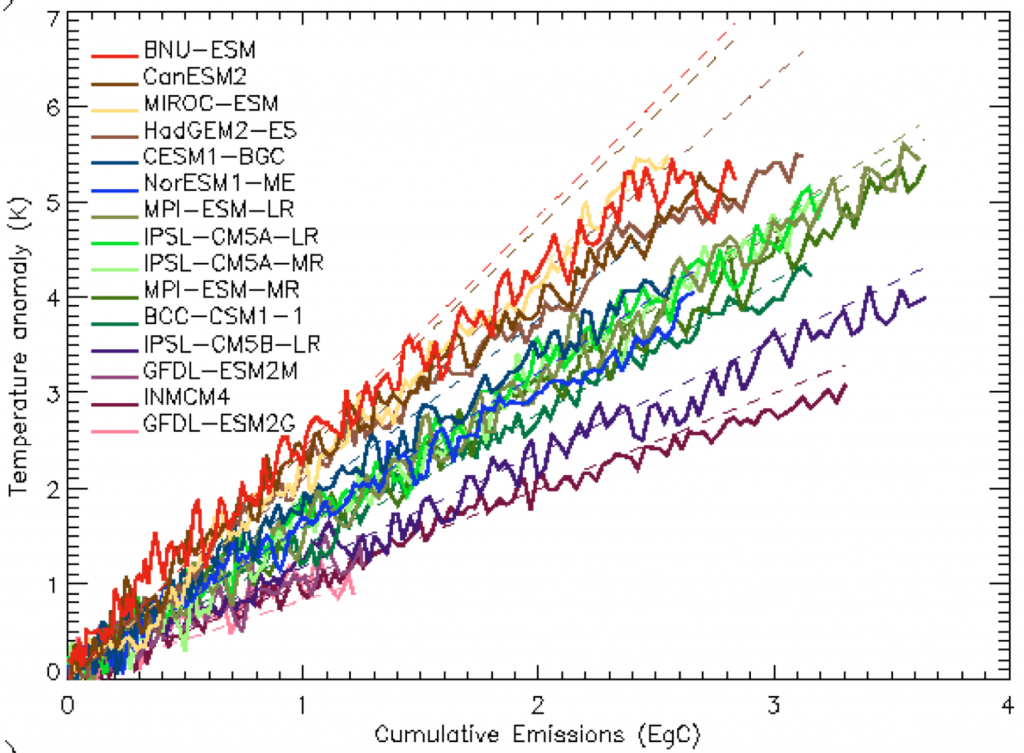
This linear relationship isn’t determined by any physical properties of the climate system, and probably won’t hold in much warmer or cooler climates, nor when other feedback processes kick in. So we could say it’s a coincidental property of our current climate. However, it’s rather fortuitous for policy discussions.
Historically, we have emitted around 550 billion tonnes since the beginning of the industrial era, which gives us an expected temperature response of around 0.9°C. If we want to hold temperature rises to be no more than 2°C of warming, total future emissions should not exceed a further 700 billion tonnes of Carbon. In effect, this gives us a total worldwide carbon budget for the future. The hard policy question, of course, is then how to allocate this budget among the nations (or people) of the world in an equitable way.
[A few years ago, I blogged about a similar analysis, which says that cumulative carbon emissions should not exceed 1 trillion tonnes in total, ever. That calculation gives us a smaller future budget of less then 500 billion tonnes. That result came from analysis using the Hadley model, which has one of the higher slopes on the graphs above. Which number we use for a global target then might depend on which model we believe gives the most accurate projections, and perhaps how we also factor in the uncertainties. If the uncertainty range across models is accurate, then picking the average would give us a 50:50 chance of staying within the temperature threshold of 2°C. We might want better odds than this, and hence a smaller budget.]
In the National Academies report in 2011, the cumulative carbon budgets for each temperature threshold were given as follows (note the size of the uncertainty whiskers on each bar):
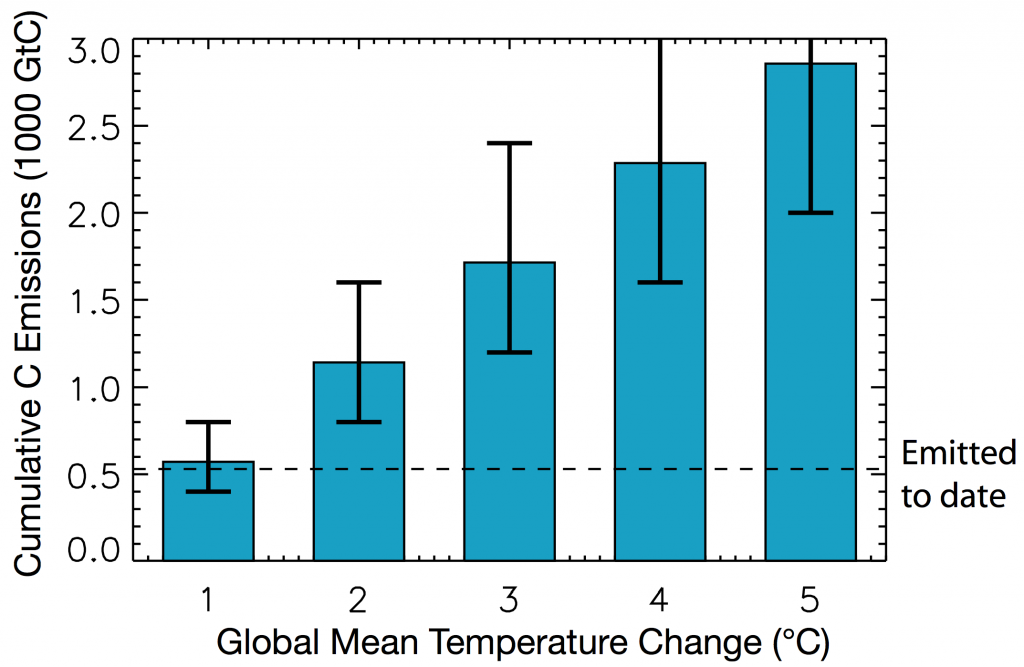
[For a more detailed analysis see: Matthews, H. D., Solomon, S., & Pierrehumbert, R. (2012). Cumulative carbon as a policy framework for achieving climate stabilization. Philosophical transactions. Series A, Mathematical, physical, and engineering sciences, 370(1974), 4365–79. doi:10.1098/rsta.2012.0064]
So, this allows us to clear up some popular misconceptions:
The idea that there is some additional warming owed, no matter what emissions pathway we follow is incorrect. Zero future emissions means little to no future warming, so future warming depends entirely on future emissions. And while the idea of zero future emissions isn’t policy-relevant (because zero emissions is impossible, at least in the near future), it does have implications for how we discuss policy choices. In particular, it means the idea that CO2 emissions cuts will not have an effect on temperature change for several decades is also incorrect. Every tonne of CO2 emissions avoided has an immediate effect on reducing the temperature response.
Another source of confusion is the emissions scenarios used in the IPCC report. They don’t diverge significantly for the first few decades, largely because we’re unlikely (and to some extent unable) to make massive emissions reductions in the next 1-2 decades, because society is very slow to respond to the threat of climate change, and even when we do respond, the amount of existing energy infrastructure that has to be rebuilt is huge. In this sense, there is some inevitable future warming, but it comes from future emissions that we cannot or will not avoid. In other words, political, socio-economic and technological inertia are the primary causes of future climate warming, rather than any properties of the physical climate system.













{kind=link}